Leistungsmerkmale der NVIDIA HGX-2
Unterstützung für den weltweit größten Grafikprozessor
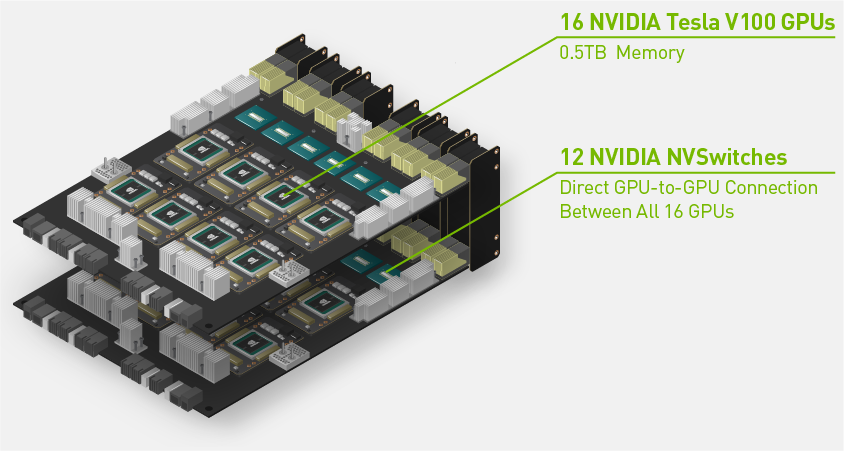
Dank der Beschleunigung durch 16 NVIDIA® Tesla® V100-Grafikprozessoren und mithilfe von NVIDIA NVSwitch™ bietet die HGX-2 eine beispiellose Rechenleistung, Bandbreite und Speichertopologie, um umfangreiche Modelle schneller zu trainieren, Datensätze zu analysieren und Simulationen schneller und effizienter zu berechnen. Die 16 Tesla V100-Grafikprozessoren agieren als einheitlicher 2-PetaFLOPS-Beschleuniger mit einem Grafikprozessor-Gesamtspeicher von einem halben Terabyte (TB), sodass damit die rechenintensivsten Aufgaben erledigt werden können und der „weltweit größte Grafikprozessor“ bereitgestellt werden kann.